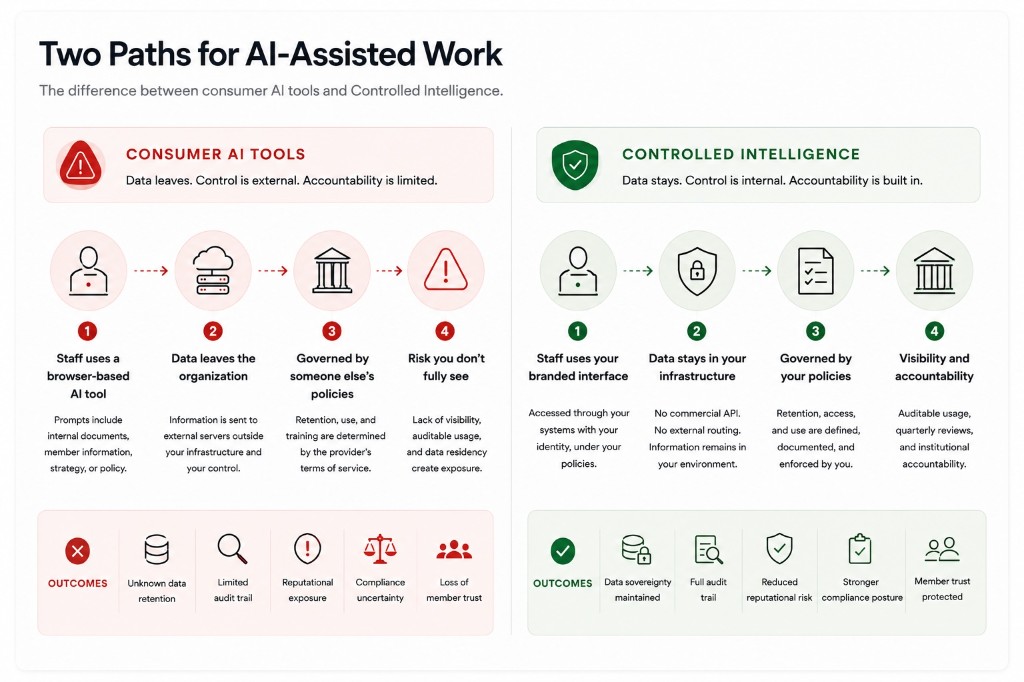
Most healthcare associations and professional bodies have at least one staff member using ChatGPT or another popular consumer AI tool regularly for their work.
They're likely using it for communications drafts, policy summaries, member correspondence, email, newsletter content. In most cases, leadership doesn't know which staff member it is, which documents have gone through the interface, or what commercial infrastructure is now holding information the organization considers internal.
This is something to clearly consider for healthcare associations and professional bodies more so than in some commercial sectors. The information traveling through browser-based AI tools (ChatGPT, Claude, Gemini, and company) is often the same information members trust the organization to protect: regulatory submissions, internal advocacy positions, member correspondence, clinical guidance. PIPEDA and PIPA set the legal floor. The reputational exposure sits above that, and it doesn't require a breach to land poorly.
We developed a strategy and framework to address these gaps. It's called Controlled Intelligence and its core layer, which we're focusing on in this post, is described below.
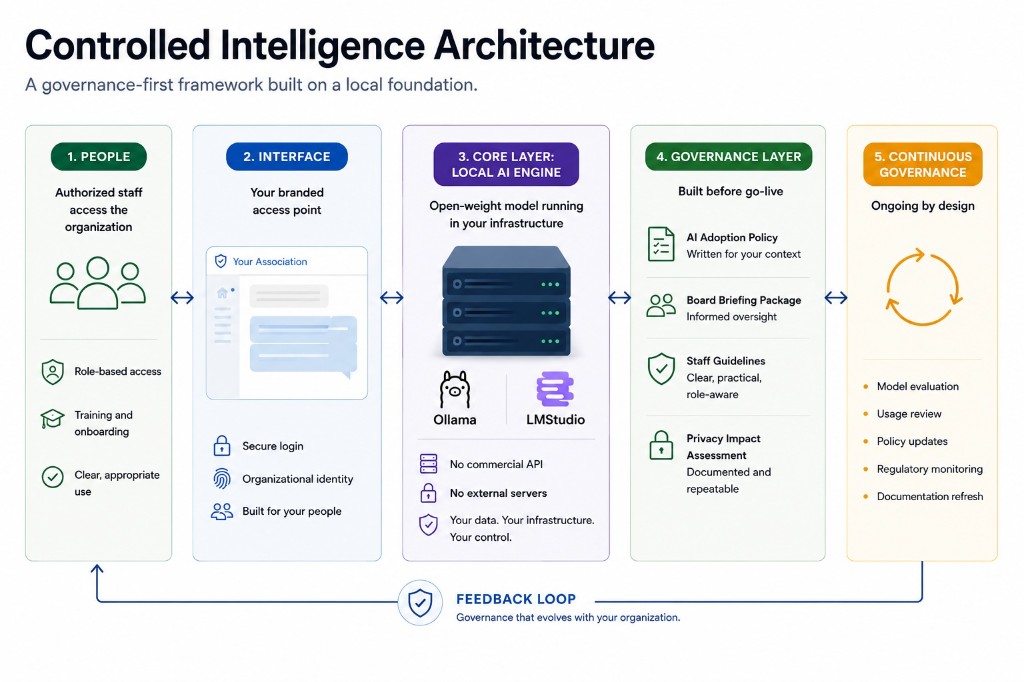
Controlled Intelligence is a governance-first AI framework built specifically for this operating context. Here's how it works.
The core layer is a locally deployed open-weight model, based on tools like Ollama, LM Studio, or others like them, running inside the organization's own secure infrastructure. No commercial API or opaque third-party licensing agreement. No data routed through an external server. The model runs on the secure network the organization already controls, under policies the organization sets.
Staff access it through a branded interface that carries the organization's identity. It looks like an organizational tool because it is one. Staff aren't moving between the association's systems and a commercial platform. The boundary between tool and institution is closed by design.
The governance layer is built before the tool goes live. That means an AI adoption policy written for the organization's actual operating context, a board briefing package, staff guidelines, and a privacy impact assessment framework, all in place before the first prompt is submitted.
Staff onboarding is calibrated to actual capacity, not to the tool's feature list.
Many organizations that have struggled with AI adoption trained staff to use a tool that wasn't fitted for the specifics of their organization and the context of its use escaped accountability and tracking.
Controlled Intelligence addresses the calibration problem alongside the access problem.
Quarterly governance reviews are built into the ongoing engagement. The model gets evaluated. Usage patterns get reviewed. The governance documentation gets updated as the tool evolves, staff knowledge improves, and as the regulatory environment shifts. This is the structure that makes the framework durable.
Commercial AI tools don't have organizational memory or organizational loyalty. They have terms of service and training pipelines. When a staff member feeds a sensitive document into ChatGPT to produce a summary, the document has left the building. Whether it remains there is governed by OpenAI's data policies, not by the association's. Most organizations have a policy document that addresses this. The policy document and the tool's actual behaviour are not the same thing.
Most member-based organizations are a few steps away from a board conversation that often gets pushed further and further down the road. A member complaint about data handling, a staff disclosure that surfaces informal AI use, a privacy inquiry from a regulator. Controlled Intelligence changes what an organization can say in that conversation, not because it produces better talking points, but because the architecture provides the answer.
The local engine is the core layer and everything else fans out from it: the staff-facing interface, the governance documents, the onboarding, the quarterly reviews. The reason to start there is that it changes what's possible in the rest of the framework. An organization running a local model can make real commitments about data custody because those commitments are true, repeatable, and provable. An organization relying on commercial tools with a policy document is relying on the document to do things that it simply can't support.
Discovery is the entry point for most engagements and can be done at any time. It produces a written organizational assessment and a board-ready implementation pathway that has value regardless of whether the organization proceeds. It's a current-state picture of AI use inside the organization, a gap analysis against existing privacy obligations, and a realistic timeline for what responsible adoption looks like given actual budget and staff capacity.
The organizations that have a clear answer to "where does our AI-assisted work actually go?" are a small minority. For most, the answer is somewhere inside a commercial platform's infrastructure, governed by a terms of service agreement the organization has never read but are bound by regardless. Controlled Intelligence changes that answer before the question gets asked in a less comfortable context.